linux常用指令
系统目录
| 目录 | 功能 |
|---|---|
| /bin | 基本系统所需要的命令,功能和"/usr/bin"类似,这个目录下的文件都是可执行的.普通用户也是可以执行的. |
| /usr | 存放用户使用系统命令和应用程序等信息.像命令.帮助文件等. |
| /sbin | 基本的系统维护命令,只能由超级用户使用. |
| /home | 普通用户的目录默认存储目录. |
| /etc | 所有的系统配置文件. |
| /boot | 内核和加载内核所需要的文件.grub系统引导管理器也在这个目录下. |
| /dev | 设备文件存储目录.像终端.磁盘等. |
| /lib | 库文件和内核模块存放目录. |
| /proc | 虚拟的目录,是系统内存的映射。可直接访问这个目录来获取系统信息。 |
| /opt | 第三方软件的存放目录. |
| /var | 存放经常变动的数据,像日志.邮件等. |
| /mnt | 临时文件系统的挂载点目录. |
| /tmp | 临时文件目录. |
| /media | 即插即用设备的挂载点自动存放在这个目录下.像U盘,cdrom/dvd自动挂载后,就会在这个目录下. |
| /srv | 存放一些服务器启动之后需要提取的数据. |
| /root | Linux超级权限用户root的跟目录. |
用户权限
| 指令 | 功能 |
|---|---|
| sudo 指令 | 用 root 身份执行某条命令 |
| useradd xixi | 创建一个用户 |
| passwd xixi | 修改用户的登陆密码 |
| userdel xixi | 删除用户 |
| su 用户名 | 用户切换(su是switch user的缩写) |
| groupadd 组名 | 添加用户组(控制多用户权限) |
| groupdel 组名 | 删除用户组 |
| usermod | 修改用户信息(添加到组等...) |
| groups 用户名 | 查看用户属于哪些组 |
| usermod -a -G 组名 用户名 | 修改用户信息(添加到组等...) |
| /etc/passwd | 用户信息配置文件 |
| /etc/group | 用户组信息 |
| /etc/shadow | 用户密码信息配置文件 |
$ usermod -a -G fe root // 添加用户root 到fe组中
$ groups root
root : root fe // 查到现在有新增组
将一个用户添加到用户组中,千万不能直接用 usermod -G groupA。这样做会使你离开其他用户组,仅仅做为 这个用户组 groupA 的成员。应该用 加上 -a 选项
文件操作
Linux 一切皆文件,文件管理
| 指令 | 功能 |
|---|---|
| ls | 列出目录 |
| cd | 切换目录 |
| pwd | 显示目前的目录 |
| touch file | 创建文件 |
| mkdir 目录 | 创建一个新的目录,mkdir -p A/B(若A不存在先创建A再创建B) |
| rmdir 目录 | 删除一个空的目录 |
| cp | 复制文件或目录 |
| rm | 移除文件或目录 |
| mv | 移动文件与目录,或修改文件与目录的名称 |
| ln -s 源 target | 创建软链接 ln -s /usr/local/lib/node-v11.13.0/bin/npm /usr/local/bin/ 配置npm软链接 |
ls(列出目录)
ls -al // 将用户目录下的所有文件列出来(含属性与隐藏档) centOS可以执行 ll 作用相同
-a :全部的文件,连同隐藏档( 开头为 . 的文件) 一起列出来(常用)
-d :仅列出目录本身,而不是列出目录内的文件数据(常用)
-l :长数据串列出,包含文件的属性与权限等等数据;(常用)
rm(删除)
rm -f file // 删除某个文件
rm -rf filer // 删除目录 -r向下删除递归,-f直接删除无提示
cp(复制)
cp [-f] file A 复制file文件到A目录下
-a:此选项通常在复制目录时使用,它保留链接、文件属性,并复制目录下的所有内容。其作用等于dpR参数组合。
-d:复制时保留链接。这里所说的链接相当于Windows系统中的快捷方式。
-f:覆盖已经存在的目标文件而不给出提示。
-i:与-f选项相反,在覆盖目标文件之前给出提示,要求用户确认是否覆盖,回答"y"时目标文件将被覆盖。
-p:除复制文件的内容外,还把修改时间和访问权限也复制到新文件中。
-r:若给出的源文件是一个目录文件,此时将复制该目录下所有的子目录和文件。
-l:不复制文件,只是生成链接文件。
# 如果备份目录envbak不存在,则可以直接使用
cp -r env envbak
# 如果目标备份dir2目录已存在,则需要使用
cp -r dir1/. dir2
# 将folder目录内容移动到当前执行目录下
cp -a ./folder/* ./
mv(移动)
# 将home下的bashrc复制到当前目录中
cp /home/.bashrc bashrc
# 创建一个目录
mkdir mvtest
# 将新复制的bashrc复制到mvtest目录中
mv bashrc mvtest
# 目录mvtest 更名为 mvtest2
mv mvtest mvtest2
# 将folder目录内容移动到当前执行目录下
mv ./folder/* ./
内容查看
- cat 由第一行开始显示文件内容
- tac 从最后一行开始显示,可以看出 tac 是 cat 的倒著写!
- nl 显示的时候,顺道输出行号!
- more 一页一页的显示文件内容
- less 与 more 类似,但是比 more 更好的是,他可以往前翻页!
- head 只看头几行
- tail 只看末尾几行
tail [-n number] 文件
cat package.json
tail -n 10 npm.log # 查看最近的10条日志
chmod命令
Linux/Unix 的文件调用权限分为三级 : 文件拥有者、群组、其他。利用 chmod 可以藉以控制文件如何被他人所调用。比如新建一个.sh脚本,提示无法执行。可能是因为权限不足导致的。
语法:chmod [-cfvR] [--help] [--version] mode file
- 文件权限
- r 读权限 4
- w 写权限 2
- x 执行权限 1
- 目录权限
- rx 进入目录读取文件名
- wx 修改目录内文件名
- x 进入目录
- 角色权限
- a all--所有用户
- u user----文件拥有着
- g group----与user同属一个group的其他user
- o other-----其他group的user
| 指令 | 功能 |
|---|---|
| 将文件 file1.txt 设为所有人皆可读取 | chmod ugo+r file1.txt / chmod a+r file1.txt |
| 将文件 file1.txt 与 file2.txt 设为该文件拥有者,与其所属同一个群体者可写入,但其他以外的人则不可写入 | chmod ug+w,o-w file1.txt file2.txt |
| 将 ex1.py 设定为只有该文件拥有者可以执行 | chmod u+x ex1.py |
| 将目前目录下的所有文件与子目录皆设为任何人可读取 | chmod -R a+r * / chmod 777 file |
chmod 777 file 语法为:chmod abc file 其中a,b,c各为一个数字,分别表示User、Group、及Other的权限。 r=4,w=2,x=1
- 若要rwx属性则4+2+1=7;
- 若要rw-属性则4+2=6;
- 若要r-x属性则4+1=5。 chmod a=rwx file 等同于 chmod 777 file chmod ug=rwx,o=x file 等同于 chmod 771 file 若用chmod 4755 filename可使此程序具有root的权限
常用形式:
chmod +x filename // 使文件可执行
chmod 777 ./deploye.sh // 将deploye.sh设为任何人可读,写,执行
chmod 777 /project/ // 将目录(即/project)设为任何人可读,写,执行
chmod 755 [filename] 意思是 u的权限是4+2+1、 g和o的权限是4+1, -rwxr-xr-x(在首位-代表普通文件,d代表目录(directory),l代表链接(link),b代表区块(block),c代表(character))
chmod a+x [filename]
chmod u+r [filename]
打包压缩
.tar
解包:tar xvf FileName.tar
打包:tar cvf FileName.tar DirName // 将整个 /DirName 目录下的文件全部打包成为 FileName.tar
(注:tar是打包,不是压缩!)
———————————————
.gz
解压1:gunzip FileName.gz
解压2:gzip -d FileName.gz
压缩:gzip FileName
.tar.gz 和 .tgz
解压:tar zxvf FileName.tar.gz
压缩:tar zcvf FileName.tar.gz DirName
———————————————
.bz2
解压1:bzip2 -d FileName.bz2
解压2:bunzip2 FileName.bz2
压缩: bzip2 -z FileName
.tar.bz2
解压:tar jxvf FileName.tar.bz2 或tar –bzip xvf FileName.tar.bz2
压缩:tar jcvf FileName.tar.bz2 DirName
———————————————
.bz
解压1:bzip2 -d FileName.bz
解压2:bunzip2 FileName.bz
压缩:未知
.tar.bz
解压:tar jxvf FileName.tar.bz
压缩:未知
———————————————
.Z
解压:uncompress FileName.Z
压缩:compress FileName
.tar.Z
解压:tar Zxvf FileName.tar.Z
压缩:tar Zcvf FileName.tar.Z DirName
———————————————
.zip
解压:unzip FileName.zip
压缩:zip FileName.zip DirName
压缩一个目录使用 -r 参数,-r 递归。例: $ zip -r FileName.zip DirName
———————————————
.rar
解压:rar x FileName.rar
压缩:rar a FileName.rar DirName
查找
grep 查找文件里符合条件的字符串 如果发现某文件的内容符合所指定的范本样式,预设 grep 指令会把含有范本样式的那一列显示出来。若不指定任何文件名称,或是所给予的文件名为 -,则 grep 指令会从当前设备(系统环境)读取数据。
- 在当前目录中,查找后缀有 file 字样的文件中包含 test 字符串的文件,并打印出该字符串的行。此时,可以使用如下命令:
grep test *file
$ grep test test* #查找前缀有“test”的文件包含“test”字符串的文件
testfile1:This a Linux testfile! #列出testfile1 文件中包含test字符的行
testfile_2:This is a linux testfile! #列出testfile_2 文件中包含test字符的行
testfile_2:Linux test #列出testfile_2 文件中包含test字符的行
- 以递归的方式查找符合条件的文件。例如,查找指定目录/home/www 及其子目录(如果存在子目录的话)下所有文件中包含字符串"foo"的文件,并打印出该字符串所在行的内容,使用的命令为:
grep -r foo /home/www
$ grep -r foo /home/www #以递归的方式查找“/home/www”
#下包含“foo”的文件
a.sh:foo="a来的"
b.sh:echo "文件a的变量:$foo"
wt.sh:foo=justwe
wt.sh:echo foo
wt.sh:echo "输出变量:foo"
wt.sh:echo '输出变量:$foo'
wt.sh:echo "输出变量:$foo"
wt.sh:# echo `输出日期:$foo` # 这条指令不能正常执行
反向查找。前面各个例子是查找并打印出符合条件的行,通过"-v"参数可以打印出不符合条件行的内容。 查找文件名中包含 test 的文件中不包含test 的行,此时,使用的命令为:
grep -v test *test*查看端口占用:
netstat -anp |grep 端口号
find
find是最常见和最强大的查找命令,你可以用它找到任何你想找的文件。
find的使用格式如下:
find <指定目录> <指定条件> <指定动作>
- <指定目录>: 所要搜索的目录及其所有子目录。默认为当前目录。
- <指定条件>: 所要搜索的文件的特征。
- <指定动作>: 对搜索结果进行特定的处理。
如果什么参数也不加,find默认搜索当前目录及其子目录,并且不过滤任何结果(也就是返回所有文件),将它们全都显示在屏幕上。
find的使用实例:
find . -name 'my*'
搜索当前目录(含子目录,以下同)中,所有文件名以my开头的文件。
find . -name 'my*' -ls
搜索当前目录中,所有文件名以my开头的文件,并显示它们的详细信息。
find . -type f -mmin -10
搜索当前目录中,所有过去10分钟中更新过的普通文件。如果不加-type f参数,则搜索普通文件+特殊文件+目录。
locate
locate 命令其实是 find -name 的另一种写法,但是要比后者快得多,原因在于它不搜索具体目录,而是搜索一个数据库(/var/lib/locatedb),这个数据库中含有本地所有文件信息。Linux系统自动创建这个数据库,并且每天自动更新一次,所以使用locate命令查不到最新变动过的文件。为了避免这种情况,可以在使用 locate 之前,先使用 updatedb 命令,手动更新数据库。
locate
locate命令的使用实例:
| 指令 | 功能 |
| ---------------- | ----------------------------------------------------- |
| locate /etc/sh | 搜索etc目录下所有以sh开头的文件 |
| locate ~/m | 搜索用户主目录下,所有以m开头的文件。 |
| locate -i ~/m | 搜索用户主目录下,所有以m开头的文件,并且忽略大小写。 |
whereis
whereis命令只能用于程序名的搜索,而且只搜索二进制文件(参数-b)、man说明文件(参数-m)和源代码文件(参数-s)。如果省略参数,则返回所有信息。
whereis grep
which
which命令的作用是,在PATH变量指定的路径中,搜索某个系统命令的位置,并且返回第一个搜索结果。也就是说,使用which命令,就可以看到某个系统命令是否存在,以及执行的到底是哪一个位置的命令。
which grep
type
type命令其实不能算查找命令,它是用来区分某个命令到底是由shell自带的,还是由shell外部的独立二进制文件提供的。如果一个命令是外部命令,那么使用-p参数,会显示该命令的路径,相当于which命令。
| 指令 | 功能 |
| -------------- | -------------------------------------------------- |
| type cd | 系统会提示,cd是shell的自带命令(build-in) |
| type grep | 系统会提示,grep是一个外部命令,并显示该命令的路径 |
| type -p grep | 加上-p参数后,就相当于which命令 |
查看内存使用
ps
ps -ef
ps –ef | grep python #(常用)查询 python 进程,grep -> 筛选
ps aux: 按照 pid 显示内容 (默认排序方式)
ps aux --sort -rss: 按照 rss 排序显示内容
top
| key | 含义 |
|---|---|
| PID | 进程的ID |
| USER | 进程所有者 |
| PR | 进程的优先级别,越小越优先被执行 |
| NI | 进程Nice值,代表这个进程的优先值 |
| VIRT | 进程占用的虚拟内存 |
| RES | 进程占用的物理内存 |
| SHR | 进程使用的共享内存 |
| S | 进程的状态。S表示休眠,R表示正在运行,Z表示僵死状态 |
| %CPU | 进程占用CPU的使用 |
| %MEM | 进程使用的物理内存和总内存的百分 |
| TIME+ | 该进程启动后占用的总的CPU时间,即占用CPU使用时间的累加值 |
| COMMAND | 启动该进程的命令名称 |
free命令:
free: 用KB为单位展示数据
free -m: 用MB为单位展示数据
free -h: 用GB为单位展示数据
| key | 含义 |
|---|---|
| total | 总计屋里内存的大小 |
| used | 已使用内存的大小 |
| free | 可用内存的大小 |
| shared | 多个进程共享的内存总额 |
| buff/cache | 磁盘缓存大小 |
| available | 可用内存大小 , 从应用程序的角度来说:available = free + buff/cache . |
cat /proc/meminfo 命令
这是用来查看RAM使用情况最简单的方法。 这个动态更新的虚拟文件实际上是许多其他内存相关工具的组合显示,就如上面说列的 top, free等。它列出了所有我们想了解的内存的使用情况。
进程的内存使用信息也可以通过: /proc//statm 和 /proc//status 来查看。
vmstat -s
查看文件夹大小,磁盘剩余空间
du查看目录大小,df查看磁盘使用情况。
df
df则是基于文件系统总体来计算,通过文件系统中未分配空间来确定系统中已经分配空间的大小。df命令可以获取硬盘占用了多少空间,还剩下多少空间,它也可以显示所有文件系统对i节点和磁盘块的使用情况。
| 指令 | 功能 |
|---|---|
| df -hl | 查看磁盘剩余空间 |
| df -h | 查看每个根路径的分区大小 |
| du -sh [目录名] | 返回该目录的大小 |
| du -sm [文件夹] | 返回该文件夹总M数 |
du
du是面向文件的命令,只计算被文件占用的空间,不计算文件系统 metadata 占用的空间
管道
把前一个命令的结果当成后一个命令的输入。
管道是由内核管理的一个缓冲区,相当于我们放入内存中的一个纸条。管道的一端连接一个进程的输出。这个进程会向管道中放入信息。管道的另一端连接一个进程的输入,这个进程取出被放入管道的信息。一个缓冲区不需要很大,它被设计成为环形的数据结构,以便管道可以被循环利用。当管道中没有信息的话,从管道中读取的进程会等待,直到另一端的进程放入信息。当管道被放满信息的时候,尝试放入信息的进程会堵塞,直到另一端的进程取出信息。当两个进程都终结的时候,管道也自动消失。
- 查看 a.txt 文件5-10行的内容
head -n10 a.txt | tail -n+5 - 查询带有关键字 python 的进程
ps –ef | grep python
常用记录
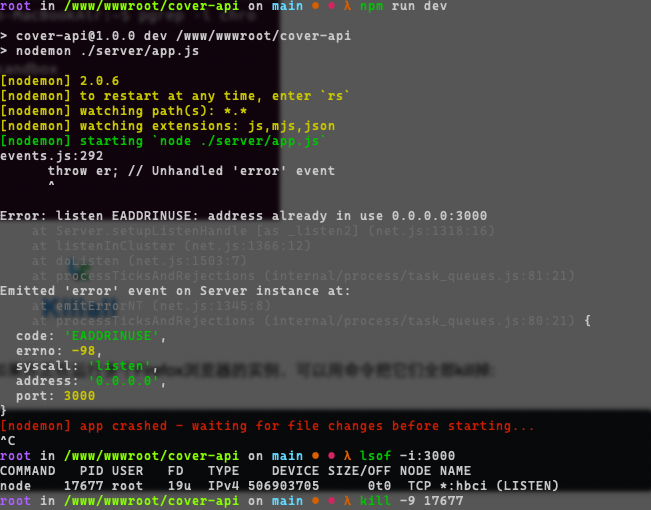
查看端口占用并停止
lsof -i:3000- 找到PID进程号,不影响的应用直接杀掉进程:
kill -9 {PID}